This work involve developing a supervised heirarchical clustering algorithm using graph neural networks for speaker diarization.
Overview
Research Interests:
Machine Learning, Speech Processing, Speaker Diarization, Signal Processing, Variational Inference, Self-supervised Learning, Graph based Clustering.
Thesis Work
Graph Clustering Approaches for Speaker Diarization
My research involves self-supervised and supervised clustering approaches for automatic speaker diarization in the context of conversational speech.
What is Speaker Diarization ?
It is the task of partitioning an audio containing multiple speakers into segments assigning labels to the corresponding speakers.
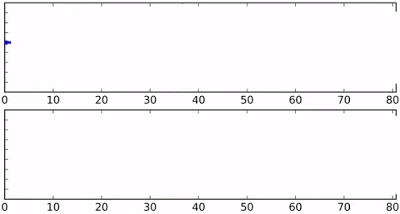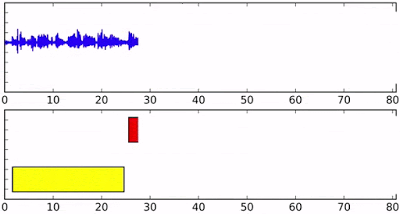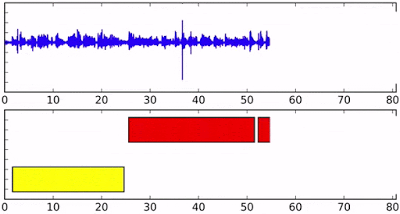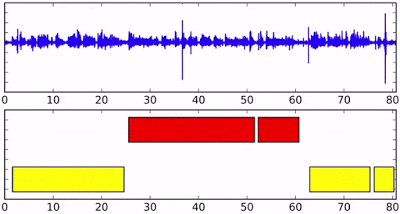
This work involves learning representations using clustering based loss. The task is self-supervised because we learn the representations using the clustering output given by the clustering algorithm to make the representations more speaker discriminative. We explored graph structural path integral clustering to encode embedding space in the form of graph. Published in IEEE Transactions on Speech, Audio and Language Processing.
The proposed approach is based on principles of self-supervised learning where the self-supervision is derived from the clustering algorithm. The representations are learnt using triplet based loss derived from clustering output from previous stage. The work is accepted in Interspeech 2020.
Contributed in baseline system setup for the DIHARD-III challenge. It involves task to partition an audio into speaker segments, in challenging environment where the audio is corrupted with noise, music, babble etc. and contains short speaker turns. It has applications in rich-text transcription of meetings, clinical diagnosis etc. Participated in challenge and was among top 10 teams across globe. Our system involved combination of End-to-End diarization based on transformers for telephone conversation and graph based clustering for multi-speaker conversations.
The project involves identifying different speakers present in different segment of a given audio recording from DIHARD dataset which has challenging scenarios including restaurants, clinical interviews, mother child conversations etc. using posterior scaled Variational Bayes - Hidden Markov Model. The work is published in Interspeech 2019.
SRE 2018 challenge involved test conditions with multiple speaker. We perform diarization to extract individual speaker segments to score against the enrollment. This work is published in ICASSP 2019.
Workshops and Conferences
- Presented in ICASSP 2023, Greece
- Presented in IISc EECS Symposium April,2022
- Presented paper in ASRU 2021
- Presented in IISc EECS Symposium May,2021
- Presented in IEEE-IISc Shannon's Day talk series, April,2021
- Presented in DIHARD-III challenge workshop 2020
- Talk on Women in Research in PyConIndia 2020, Online
- Winter School on Speech and Audio Processing (WiSSAP) 2020,IIT Mandi, India
- Presented paper and poster in Interspeech 2019, Graz, Austria
- Summer school on mathematics for data science 2019 organised by IFCAM and IISc
- Winter School on Speech and Audio Processing (WiSSAP) 2019, Trivandrum, India
- Interspeech 2018, Hyderabad, India
- Brain Computation and Learning Workshop, 2018, Bangalore, India
- International Conference on Signal Processing and Communications(SPCOM), 2018